スポンサード リンク
フリーソフトのPDF XChange Viewer(無料版)のOCR機能と、有料製品の読んde!!ココ Ver.13 (エプソン)のOCR機能を比較してみました。
FUJITSU ScanSnap S1500
(エプソン)のOCR機能を比較してみました。
FUJITSU ScanSnap S1500
のデフォルト設定でPDF化した少し古い本(元サイズB5版位)の1ページです。

まずは、PDF Xchange Viewer(無料版)のOCR機能を使ってテキスト情報を抽出します。
やり方は、ツールバーのOCRボタンを押して出てきたダイアログボックスでページ指定と、Primary Language をJapaneseに変更してOKを。
メニューの、ツール(T)→基本ツール→選択ツール(L)でカーソルが手袋から矢印に変わったら文章上でドラッグすると選択状態になります。
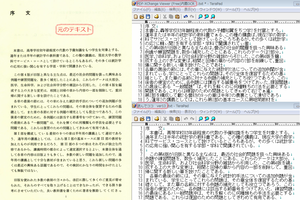
テキスト選択後コピーして、メモ帳に貼り付けたものがこちら。
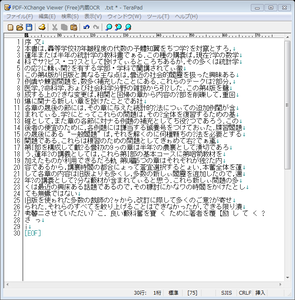
だいぶがんばっているようですが、すんなりとは読めませんね。
これが「透明テキスト」の中身なのですが、この認識レベルだと、後で特定の文字列を全文検索などしても引っかかりそうにありません。何しろ元ファイルがこれだけ崩れていては。
そして、読んでココ(正しくは、読んde!!ココ)。
このソフトは、昔に購入したEPSONフラットヘッドスキャナにバンドル(付属)していたパーソナル版からアップグレード購入(
読んde!!ココ Ver.13 アップグレード版 for ダウンロード [ダウンロード]
)したものです。
読んでココを立ちあげて、メニューの、ファイル(F)→PDFファイルから取り込む→ファイル名指定→ページ番号指定後、このような画面になるので、
ここでクリップボードに転送を押すと、認識結果のテキスト情報がコピーされるので、これもまた、メモ帳に貼り付けました。
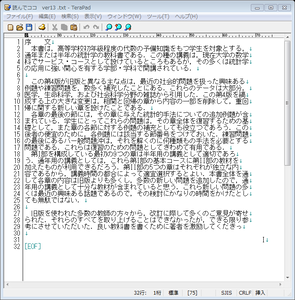
コチラは前と違ってほぼ完全に認識されていてストレスなく読むことができます。
並べて比較してみました。
まとめ
国産有料ソフトでは、ここまで完全に認識されるなら、文章だけの小説本などはPDFファイルのままで閲覧するよりも、少しだけ手間はかかりますが、OCR→テキストファイル化することによって文字サイズやフォントの変更が出来るようになるので、他のソフトや電子ブックリーダーやスマートフォン等にに送った時に格段に読みやすくなると思います。
スポンサード リンク
PR






